


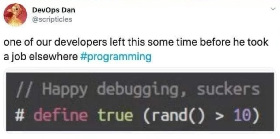
define it as ( __LINE__ % 10) so that the problem goes away when you add a debug statement
Makes the error a little too frequent, but does obscure any performance penalty and is some truly evil genius work!
That exact version will end up making “true” false any time it appears on a line number that is divisible by 10.
During the compilation, “true” would be replaced by that statement and within the statement, “__LINE__” would be replaced by the line number of the current line. So at runtime, you end up witb the line number modulo 10 (%10). In C, something is true if its value is not 0. So for e.g., lines 4, 17, 116, 39, it ends up being true. For line numbers that can be divided by 10, the result is zero, and thus false.
In reality the compiler would optimise that modulo operation away and pre-calculate the result during compilation.
The original version constantly behaves differently at runtime, this version would always give the same result… Unless you change any line and recompile.
The original version is also super likely to be actually true. This version would be false very often. You could reduce the likelihood by increasing the 10, but you can’t make it too high or it will never be triggered.
One downside compared to the original version is that the value of “true” can be 10 different things (anything between 0 and 9), so you would get a lot more weird behaviour since “1 == true” would not always be true.
A slightly more consistent version would be
((__LINE__ % 10) > 0)

The original version constantly behaves differently at runtime
It actually doesn’t, since rand() is deterministic.
When no seed value is specified, rand() is automatically seeded with 1 at the initial call within any program It then uses the previous output as seed for the next, so it will always have the same output sequence

__LINE__ returns the line of code its on, and % 10 means “remainder 10.” Examples:
1 % 10 == 1
...
8 % 10 == 8
9 % 10 == 9
10 % 10 == 0 <-- loops back to 0
11 % 10 == 1
12 % 10 == 2
...
19 % 10 == 9
20 % 10 == 0
21 % 10 == 1
In code, 0 means false and 1 (and 2, 3, 4, …) means true.
So, if on line 10, you say:
int dont_delete_database = true;
then it will expand to:
int dont_delete_database = ( 10 % 10 );
// 10 % 10 == 0 which means false
// database dies...
if you add a line before it, so that the code moves to line 11, then suddenly it works:
// THIS COMMENT PREVENTS DATABASE FROM DYING
int dont_delete_database = ( 11 % 10 );
// 11 % 10 == 1, which means true
__ LINE __ is a preprocessor macro. It will be replaced with the line number it is written on when the code is compiled. Macros aren’t processed when debugging. So the code will be skipped during debug but appear in the compiled program, meaning the program will work fine during debug but occasionally not work after compile.
“__ LINE __ % 10” returns 0 if the line number is divisible by 10 and non-zero if not. 0 is considered false and non-zero is considered true.
#define is also macro. In this case, it will replace all instances of “true” with something that will only sometimes evaluate to true when the program is compiled.

Decades ago I had to debug a random crash. It only happened on Wednesdays. On Wednesdays in September. On Wednesdays in September after the 10th…
only when your coordinates were within a train depot in Poland?
I kinda want to hear more of this story… care to share the details? i.e. what was the root cause?
It was pure c code that was used to print reports, and included the date in a header. Whoever wrote it miscalculated the size of the buffer for the header by one byte. When the date was the longest month & day spelled out plus a two digit day of the month then it would overflow the buffer, resulting in the program crashing.
This wouldn’t pass PR review and automated tests, unless they were a senior dev and used elevated privileges to mess with things behind the scenes.
It’s bold to assume those exist. Maybe there’s a reason the coworker left
rand() will be infrequent < 10 (at least ten in 2^15 times, if not exponentially more), so automated tests are likely to pass. If they don’t, they’re likely to pass on the second try, and then everyone shrugs and continues. If it’s buried in 500 other lines, then it’s likely the code reviewer will give it all a quick scan and say “it’s fine”. It’s the three line diffs that get lots of scrutiny.
In other words, you seem to have a lot more faith in the process than I do.

rand will be called every time true is used, which could be hundreds of times for all we know
If it’s a 16-bit integer platform, it might hit every once in a while.
If it’s a 32-bit integer platform, it’ll hit very rarely.
If it’s a 64-bit integer platform, someone would have to do the math with some reasonable assumptions, but I wouldn’t be surprised if it would never hit before the universe becomes nothing but black holes.

Write a 5 line PR and receive 5 comments. Write a 500 line PR and receive no comments.

Yeah but even a single automated test would catch it and reject the PR. You just need a single test.
No, you can’t assume that. The probability of hitting the condition each time is low. If there aren’t very many calls that hit this, it could easily slip through. Especially on 64-bit int platforms.
Funny but I call bullshit all day
That happened 🙄
Lol I don’t think the preprocessor would be too happy with a space after #



{kind=link}
{kind=link}