


alt text
Caption
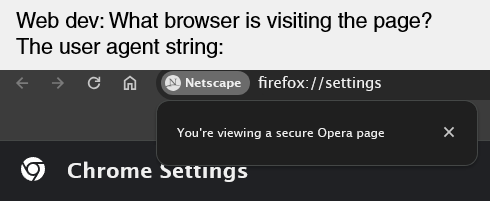
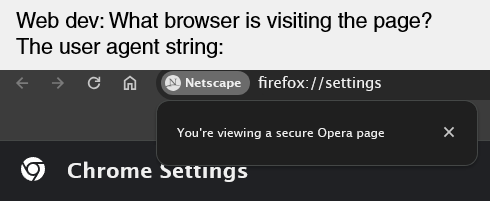
Web dev: What browser is visiting the page?
User agent string:
A screenshot of a browser. The URL bar reads firefox://settings, a button on the URL bar is labelled Netscape, a popup from the button reads: “You’re viewing a secure Opera page”, and the web page title reads “Chrome settings”.
Functionally useless. With the web standardized, we shouldn’t need user agents anyway. It would be more beneficial to ask “do you support X, Y, and Z?”
Youtube currently (for weeks now) does not work on Firefox, if you don’t use a Firefox user agent. Google doing sketchy things again.

I’ve not run into this issue and use Firefox exclusively with ublock origin
Uh… I use librewolf that force a chrome + windows user agent and its totally fine?

What works? YT on Firefox or YT on Firefox when the user agent is changed?


I know Safari 15.3 doesn’t support feature Y, but I also know the current version does. Now I want to know if I can just use the feature or if I need to program around Safari 15.3. It would be nice to just look at the server logs from last month and see if someone still uses it.

It’s called feature detection and it goes a long way back, even before Modernizr popularized it.


Most developers just write their own feature checks (a lot of detections are just a single line of code) or use a library that polyfills the feature if it’s missing.
The person you’re replying to is right, though. Modernizr popularized this approach. It predates npm, and npm still isn’t their main distribution method, so the npm download numbers don’t mean anything.

User agents are useful for checking if the request was made by a (legitimate self-identifying) bot, such as Googlebot.
It could also be used in some specific scenarios where you control the client and want to easily identify your client traffic in request logs.
Or maybe you offer a download on your site and you want to reorder your list to highlight the most likely correct binary for the platform in the user agent.
There are plenty of reasonable uses for user agent that have nothing to do with feature detection.
Aren’t user agents just a plain text header? Couldn’t a malicious agent just spoof a legitimate one?
That’s correct, it is just plain text and it can easily be spoofed. You should never perform an auth check of any kind with the user agent.
In the above examples, it wouldn’t really matter if someone spoofed the header as there generally isn’t a benefit to the malicious agent.
Where some sites get into trouble though is if they have an implicit auth check using user agents. An example could be a paywalled recipe site. They want the recipe to be indexed by Google. If I spoof my user agent to be Googlebot, I’ll get to view the recipe content they want indexed, bypassing the paywall.
But, an example of a more reasonable use for checking user agent strings for bots might be regional redirects. If a new user comes to my site, maybe I want to redirect to a localized version at a different URL based on their country. However, I probably don’t want to do that if the agent is a bot, since the bot might be indexing a given URL from anywhere. If someone spoofed their user agent and they aren’t redirected, no big deal.
User agents are essentially deprecated and are going to become less and less useful over time. The replacement is either client hints or feature detection, depending on what you’re using it for.
A URL is not an agent string, just saying.
A new browser touches the beacon

Is it… (scrolls wheel of browsers) Lynx?
I’m still amazed at how usable Lynx is, given the insane premise of the application.
What’s so insane about it? Web browsers are an evolution of the old gopher protocol. All this stuff has roots in text consoles.



{kind=link}
{kind=link}