


Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
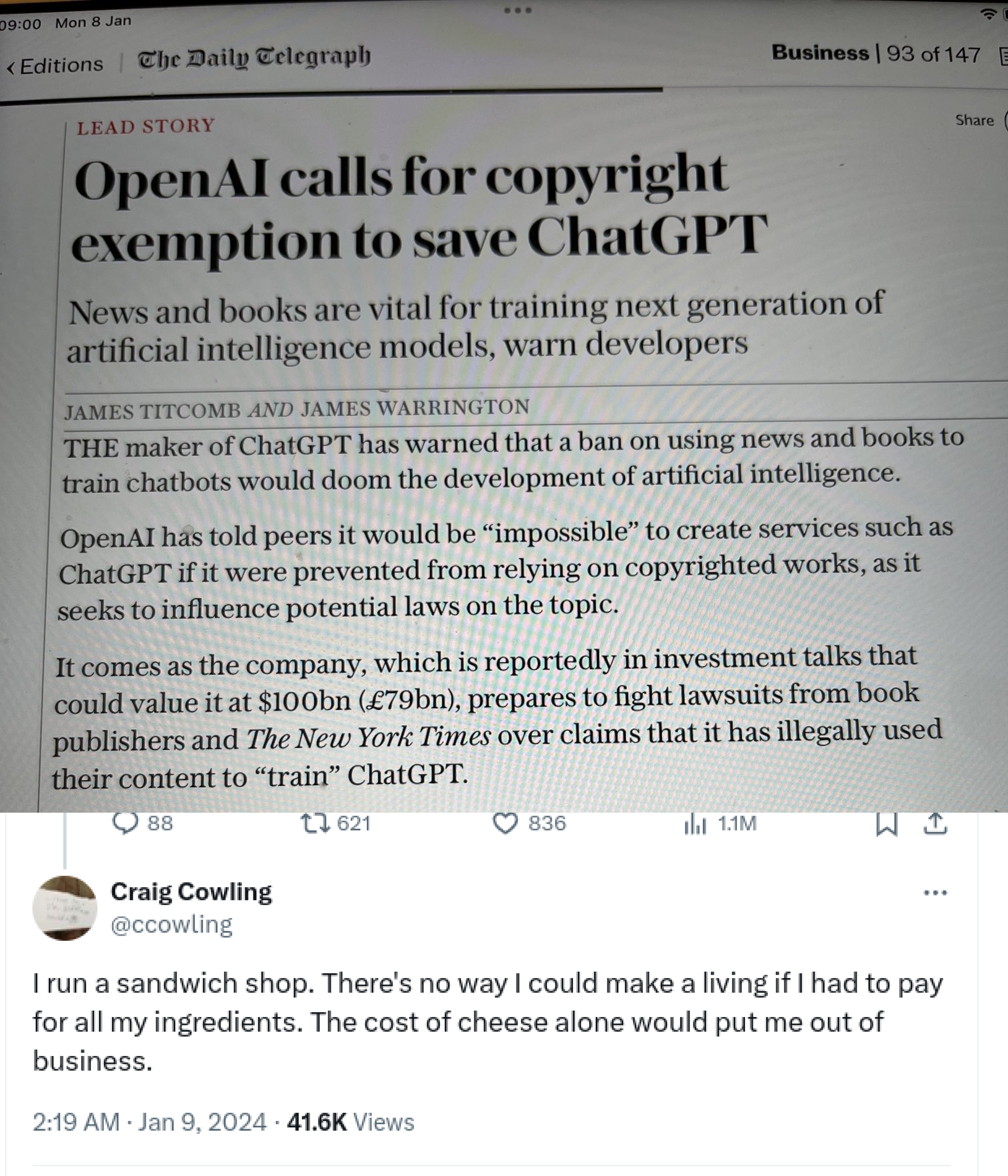
If they can base their business on stealing, then we can steal their AI services, right?

Pirating isn’t stealing but yes the collective works of humanity should belong to humanity, not some slimy cabal of venture capitalists.

ingredients to a recipe may well be subject to copyright, which is why food writers make sure their recipes are “unique” in some small way. Enough to make them different enough to avoid accusations of direct plagiarism.
E: removed unnecessary snark
Unlike regular piracy, accessing “their” product hosted on their servers using their power and compute is pretty clearly theft. Morally correct theft that I wholeheartedly support, but theft nonetheless.
Is that how this technology works? I’m not the most knowledgeable about tech stuff honestly (at least by Lemmy standards).
Yes, that’s exactly the point. It should belong to humanity, which means that anyone can use it to improve themselves. Or to create something nice for themselves or others. That’s exactly what AI companies are doing. And because it is not stealing, it is all still there for anyone else. Unless, of course, the copyrightists get there way.
How do you feel about Meta and Microsoft who do the same thing but publish their models open source for anyone to use?
Well how long to you think that’s going to last? They are for-profit companies after all.
Those aren’t open source, neither by the OSI’s Open Source Definition nor by the OSI’s Open Source AI Definition.
The important part for the latter being a published listing of all the training data. (Trainers don’t have to provide the data, but they must provide at least a way to recreate the model given the same inputs).
Data information: Sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data. Data information shall be made available with licenses that comply with the Open Source Definition.
They are model-available if anything.
For the purposes of this conversation. That’s pretty much just a pedantic difference. They are paying to train those models and then providing them to the public to use completely freely in any way they want.
It would be like developing open source software and then not calling it open source because you didn’t publish the market research that guided your UX decisions.




{kind=link}
{kind=link}
{kind=link}