


Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
If they can base their business on stealing, then we can steal their AI services, right?

Pirating isn’t stealing but yes the collective works of humanity should belong to humanity, not some slimy cabal of venture capitalists.

ingredients to a recipe may well be subject to copyright, which is why food writers make sure their recipes are “unique” in some small way. Enough to make them different enough to avoid accusations of direct plagiarism.
E: removed unnecessary snark
Unlike regular piracy, accessing “their” product hosted on their servers using their power and compute is pretty clearly theft. Morally correct theft that I wholeheartedly support, but theft nonetheless.
Is that how this technology works? I’m not the most knowledgeable about tech stuff honestly (at least by Lemmy standards).
Yes, that’s exactly the point. It should belong to humanity, which means that anyone can use it to improve themselves. Or to create something nice for themselves or others. That’s exactly what AI companies are doing. And because it is not stealing, it is all still there for anyone else. Unless, of course, the copyrightists get there way.
How do you feel about Meta and Microsoft who do the same thing but publish their models open source for anyone to use?
Well how long to you think that’s going to last? They are for-profit companies after all.
Those aren’t open source, neither by the OSI’s Open Source Definition nor by the OSI’s Open Source AI Definition.
The important part for the latter being a published listing of all the training data. (Trainers don’t have to provide the data, but they must provide at least a way to recreate the model given the same inputs).
Data information: Sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data. Data information shall be made available with licenses that comply with the Open Source Definition.
They are model-available if anything.
For the purposes of this conversation. That’s pretty much just a pedantic difference. They are paying to train those models and then providing them to the public to use completely freely in any way they want.
It would be like developing open source software and then not calling it open source because you didn’t publish the market research that guided your UX decisions.
Here’s an experiment for you to try at home. Ask an AI model a question, copy a sentence or two of what they give back, and paste it into a search engine. The results may surprise you.
And stop comparing AI to humans but then giving AI models more freedom. If I wrote a paper I’d need to cite my sources. Where the fuck are your sources ChatGPT? Oh right, we’re not allowed to see that but you can take whatever you want from us. Sounds fair.
Not to fully argue against your point, but I do want to push back on the citations bit. Given the way an LLM is trained, it’s not really close to equivalent to me citing papers researched for a paper. That would be more akin to asking me to cite every piece of written or verbal media I’ve ever encountered as they all contributed in some small way to way that the words were formulated here.
Now, if specific data were injected into the prompt, or maybe if it was fine-tuned on a small subset of highly specific data, I would agree those should be cited as they are being accessed more verbatim. The whole “magic” of LLMs was that it needed to cross a threshold of data, combined with the attentional mechanism, and then the network was pretty suddenly able to maintain coherent sentences structure. It was only with loads of varied data from many different sources that this really emerged.
This is the catch with OPs entire statement about transformation. Their premise is flawed, because the next most likely token is usually the same word the author of a work chose.
And that’s kinda my point. I understand that transformation is totally fine but these LLM literally copy and paste shit. And that’s still if you are comparing AI to people which I think is completely ridiculous. If anything these things are just more complicated search engines with half the usefulness. If I search online about how to change a tire I can find some reliable sources to do so. If I ask AI how to change a tire it would just spit something out that might not even be accurate and I’d have to search again afterwards just to make sure what it told me was even accurate.
It’s just a word calculator based on information stolen from people without their consent. It has no original thought process so it has no way to transform anything. All it can do is copy and paste in different combinations.
It’s not a breach of copyright or other IP law not to cite sources on your paper.
Getting your paper rejected for lacking sources is also not infringing in your freedom. Being forced to pay damages and delete your paper from any public space would be infringement of your freedom.
I’m pretty sure that it’s true that citing sources isn’t really relevant to copyright violation, either you are violating or not. Saying where you copied from doesn’t change anything, but if you are using some ideas with your own analysis and words it isn’t a violation either way.
I mean, you’re not necessarily wrong. But that doesn’t change the fact that it’s still stealing, which was my point. Just because laws haven’t caught up to it yet doesn’t make it any less of a shitty thing to do.

When I analyze a melody I play on a piano, I see that it reflects the music I heard that day or sometimes, even music I heard and liked years ago.
Having parts similar or a part that is (coincidentally) identical to a part from another song is not stealing and does not infringe upon any law.
The original source material is still there. They just made a copy of it. If you think that’s stealing then online piracy is stealing as well.
The argument that these models learn in a way that’s similar to how humans do is absolutely false, and the idea that they discard their training data and produce new content is demonstrably incorrect. These models can and do regurgitate their training data, including copyrighted characters.
And these things don’t learn styles, techniques, or concepts. They effectively learn statistical averages and patterns and collage them together. I’ve gotten to the point where I can guess what model of image generator was used based on the same repeated mistakes that they make every time. Take a look at any generated image, and you won’t be able to identify where a light source is because the shadows come from all different directions. These things don’t understand the concept of a shadow or lighting, they just know that statistically lighter pixels are followed by darker pixels of the same hue and that some places have collections of lighter pixels. I recently heard about an ai that scientists had trained to identify pictures of wolves that was working with incredible accuracy. When they went in to figure out how it was identifying wolves from dogs like huskies so well, they found that it wasn’t even looking at the wolves at all. 100% of the images of wolves in its training data had snowy backgrounds, so it was simply searching for concentrations of white pixels (and therefore snow) in the image to determine whether or not a picture was of wolves or not.

Even if they learned exactly like humans do, like so fucking what, right!? Humans have to pay EXORBITANT fees for higher education in this country. Arguing that your bot gets socialized education before the people do is fucking absurd.

That seems more like an argument for free higher education rather than restricting what corpuses a deep learning model can train on
Basing your argument around how the model or training system works doesn’t seem like the best way to frame your point to me. It invites a lot of mucking about in the details of how the systems do or don’t work, how humans learn, and what “learning” and “knowledge” actually are.
I’m a human as far as I know, and it’s trivial for me to regurgitate my training data. I regularly say things that are either directly references to things I’ve heard, or accidentally copy them, sometimes with errors.
Would you argue that I’m just a statistical collage of the things I’ve experienced, seen or read?
My brain has as many copies of my training data in it as the AI model, namely zero, but “Captain Picard of the USS Enterprise sat down for a rousing game of chess with his friend Sherlock Holmes, and then Shakespeare came in dressed like Mickey mouse and said ‘to be or not to be, that is the question, for tis nobler in the heart’ or something”. Direct copies of someone else’s work, as well as multiple copyright infringements.
I’m also shit at drawing with perspective. It comes across like a drunk toddler trying their hand at cubism.
Arguing about how the model works or the deficiencies of it to justify treating it differently just invites fixing those issues and repeating the same conversation later. What if we make one that does work how humans do in your opinion? Or it properly actually extracts the information in a way that isn’t just statistically inferred patterns, whatever the distinction there is? Does that suddenly make it different?
You don’t need to get bogged down in the muck of the technical to say that even if you conceed every technical point, we can still say that a non-sentient machine learning system can be held to different standards with regards to copyright law than a sentient person. A person gets to buy a book, read it, and then carry around that information in their head and use it however they want. Not-A-Person does not get to read a book and hold that information without consent of the author.
Arguing why it’s bad for society for machines to mechanise the production of works inspired by others is more to the point.
Computers think the same way boats swim. Arguing about the difference between hands and propellers misses the point that you don’t want a shrimp boat in your swimming pool. I don’t care why they’re different, or that it technically did or didn’t violate the “free swim” policy, I care that it ruins the whole thing for the people it exists for in the first place.
I think all the AI stuff is cool, fun and interesting. I also think that letting it train on everything regardless of the creators wishes has too much opportunity to make everything garbage. Same for letting it produce content that isn’t labeled or cited.
If they can find a way to do and use the cool stuff without making things worse, they should focus on that.
Arguing why it’s bad for society for machines to mechanise the production of works inspired by others is more to the point.
I agree, but the fact that shills for this technology are also wrong about it is at least interesting.
Rhetorically speaking, I don’t know if that’s useless.
I don’t care why they’re different, or that it technically did or didn’t violate the “free swim” policy,
I do like this point a lot.
If they can find a way to do and use the cool stuff without making things worse, they should focus on that.
I do miss when the likes of cleverbot was just a fun novelty on the Internet.
I’m not the above poster, but I really appreciate your argument. I think many people overcorrect in their minds about whether or not these models learn the way we do, and they miss the fact that they do behave very similarly to parts of our own systems. I’ve generally found that that overcorrection leads to bad arguments about copyright violation and ethical concerns.
However, your point is very interesting (and it is thankfully independent of that overcorrection). We’ve never had to worry about nonhuman personhood in any amount of seriousness in the past, so it’s strangely not obvious despite how obvious it should be: it’s okay to treat real people as special, even in the face of the arguable personhood of a sufficiently advanced machine. One good reason the machine can be treated differently is because we made it for us, like everything else we make.
I think there still is one related but dangling ethical question. What about machines that are made for us but we decide for whatever reason that they are equivalent in sentience and consciousness to humans?
A human has rights and can take what they’ve learned and make works inspired by it for money, or for someone else to make money through them. They are well within their rights to do so. A machine that we’ve decided is equivalent in sentience to a human, though… can that nonhuman person go take what it’s learned and make works inspired by it so that another person can make money through them?
If they SHOULDN’T be allowed to do that, then it’s notable that this scenario is only separated from what we have now by a gap in technology.
If they SHOULD be allowed to do that (which we could make a good argument for, since we’ve agreed that it is a sentient being) then the technology gap is again notable.
I don’t think the size of the technology gap actually matters here, logically; I think you can hand-wave it away pretty easily and apply it to our current situation rather than a future one. My guess, though, is that the size of the gap is of intuitive importance to anyone thinking about it (I’m no different) and most people would answer one way or the other depending on how big they perceive the technology gap to be.
Another good question is why AIs do not mindlessly regurgitate source material. The reason is that they have access to so much copyrighted material. If they were trained on only one book, they would constantly regurgitate material from that one book. Because it’s trained on many (millions) books, it’s able to get creative. So the argument of OpenAI really boils down to: “we are not breaking copyright law, because we have used sufficient copyrighted material to avoid directly infringing on copyright”.
Eeeh, I still think diving into the weeds of the technical is the wrong way to approach it. Their argument is that training isn’t copyright violation, not that sufficient training dilutes the violation.
Even if trained only on one source, it’s quite unlikely that it would generate copyright infringing output. It would be vastly less intelligible, likely to the point of overtly garbled words and sentences lacking much in the way of grammar.
If what they’re doing is technically an infringement or how it works is entirely aside from a discussion on if it should be infringement or permitted.
I am also not really getting the argument. If I as a human want to learn a subject from a book I buy it ( or I go to a library who paid for it). If it’s similar to how humans learn, it should cost equally much.
The issue is of course that it’s not at all similar to how humans learn. It needs VASTLY more data to produce something even remotely sensible. Develop AI that’s truly transformative, by making it as efficient as humans are in learning, and the cost of paying for copyright will be negligible.
If I as a human want to learn a subject from a book, I buy it
xD
That’s good.
Dude never heard of a library. I only bought a handful of books during my degree, I would’ve been homeless if I had to buy a copy of every learning source
If I as a human want to learn a subject from a book I buy it ( or I go to a library who paid for it). If it’s similar to how humans learn, it should cost equally much.
You’re on Lemmy where people casually says “piracy is morally the right thing to do”, so I’m not sure this argument works on this platform.
I know my way around the Jolly Roger myself. At the same time using copyrighted materials in a commercial setting (as OpenAI does) shouldn’t be free.
Devil’s Advocate:
How do we know that our brains don’t work the same way?
Why would it matter that we learn differently than a program learns?
Suppose someone has a photographic memory, should it be illegal for them to consume copyrighted works?
Because we’re talking pattern recognition levels of learning. At best, they’re the equivalent of parrots mimicking human speech. They take inputs and output data based on the statistical averages from their training sets - collaging pieces of their training into what they think is the right answer. And I use the word think here loosely, as this is the exact same process that the Gaussian blur tool in Photoshop uses.
This matters in the context of the fact that these companies are trying to profit off of the output of these programs. If somebody with an eidetic memory is trying to sell pieces of works that they’ve consumed as their own - or even somebody copy-pasting bits from Clif Notes - then they should get in trouble; the same as these companies.
Given A and B, we can understand C. But an LLM will only be able to give you AB, A(b), and B(a). And they’ve even been just spitting out A and B wholesale, proving that they retain their training data and will regurgitate the entirety of copyrighted material.
The solution is any AI must always be released on a strong copyleft and possibly abolish copyright outright has it has only served the powerful by allowing them to enclose humanity common intellectual heritage (see Disney’s looting and enclosing if ancestral children stories). If you choose to strengthen the current regime, don’t expect things to improve for you as an irrelevant atomised individual,

The whole point of copyright in the first place, is to encourage creative expression, so we can have human culture and shit.
The idea of a “teensy” exception so that we can “advance” into a dark age of creative pointlessness and regurgitated slop, where humans doing the fun part has been made “unnecessary” by the unstoppable progress of “thinking” machines, would be hilarious, if it weren’t depressing as fuck.

The whole point of copyright in the first place, is to encourage creative expression
…within a capitalistic framework.
Humans are creative creatures and will express themselves regardless of economic incentives. We don’t have to transmute ideas into capital just because they have “value”.

Sorry buddy, but that capitalistic framework is where we all have to exist for the forseeable future.
Giving corporations more power is not going to help us end that.


Humans are indeed creative by nature, we like making things. What we don’t naturally do is publish, broadcast and preserve our work.
Society is iterative. What we build today, we build mostly out of what those who came before us built. We tell our versions of our forefathers’ stories, we build new and improved versions of our forefather’s machines.
A purely capitalistic society would have infinite copyright and patent durations, this idea is mine, it belongs to me, no one can ever have it, my family and only my family will profit from it forever. Nothing ever improves because improving on an old idea devalues the old idea, and the landed gentry can’t allow that.
A purely communist society immediately enters whatever anyone creates into the public domain. The guy who revolutionizes energy production making everyone’s lives better is paid the same as a janitor. So why go through all the effort? Just sweep the floors.
At least as designed, our idea of copyright is a compromise. If you have an idea, we will grant you a limited time to exclusively profit from your idea. You may allow others to also profit at your discretion; you can grant licenses, but that’s up to you. After the time is up, your idea enters the public domain, and becomes the property and heritage of humanity, just like the Epic of Gilgamesh. Others are free to reproduce and iterate upon your ideas.
I’d agree, but here’s one issue with that: we live in reality, not in a post-capitalist dreamworld.
Creativity takes up a lot of time from the individual, while a lot of us are already working two or even three jobs, all on top of art. A lot of us have to heavily compromise on a lot of things, or even give up our dreams because we don’t have the time for that. Sure, you get the occasional “legendary metal guitarist practiced so much he even went to the toilet with a guitar”, but many are so tired from their main job, they instead just give up.
Developing game while having a full-time job feels like crunching 24/7, while only around 4 is going towards that goal, which includes work done on my smartphone at my job. Others just outright give up. This shouldn’t be the normal for up and coming artists.
That’s why we should look for good solutions to societal problems, and not fall back on bad “solutions” just because that’s what we’re used to. I’m not against the idea of copyright existing. But copyright as it exists today is stifling and counterproductive for most creative endeavors. We do live in reality, but I don’t believe it is the only possible reality. We’re not getting to Star Trek Space Communism™ anytime soon and honestly I like the idea of owning stuff. That doesn’t mean that there aren’t concrete steps we can and should take right now in the present reality to make things better. And for that to happen we need to get our priorities and philosophies straight. Philosophies which for me include a robust public commons, the inability to own ideas outright, and the ability to take and transform art and culture. Otherwise, we’re just falling into the “temporarily embarrassed millionaires” mindset but for art and culture.
Honestly, that’s why open source AI is such a good thing for small creatives. Hate it or love it, anyone wielding AI with the intention to make new expression will be much more safe and efficient to succeed until they can grow big enough to hire a team with specialists. People often look at those at the top but ignore the things that can grow from the bottom and actually create more creative expression.
That’s the reason we got copyright, but I don’t think that’s the only reason we could want copyright.
Two good reasons to want copyright:
- Accurate attribution
- Faithful reproduction
Accurate attribution:
Open source thrives on the notion that: if there’s a new problem to be solved, and it requires a new way of thinking to solve it, someone will start a project whose goal is not just to build new tools to solve the problem but also to attract other people who want to think about the problem together.
If anyone can take the codebase and pretend to be the original author, that will splinter the conversation and degrade the ability of everyone to find each other and collaborate.
In the past, this was pretty much impossible because you could check a search engine or social media to find the truth. But with enshittification and bots at every turn, that looks less and less guaranteed.
Faithful reproduction:
If I write a book and make some controversial claims, yet it still provokes a lot of interest, people might be inclined to publish slightly different versions to advance their own opinions.
Maybe a version where I seem to be making an abhorrent argument, in an effort to mitigate my influence. Maybe a version where I make an argument that the rogue publisher finds more palatable, to use my popularity to boost their own arguments.
This actually happened during the early days of publishing, by the way! It’s part of the reason we got copyright in the first place.
And again, it seems like this would be impossible to get away with now, buuut… I’m not so sure anymore.
—
Personally:
I favor piracy in the sense that I think everyone has a right to witness culture even if they can’t afford the price of admission.
And I favor remixing because the cultural conversation should be an active read-write two-way street, no just passive consumption.
But I also favor some form of licensing, because I think we have a duty to respect the integrity of the work and the voice of the creator.
I think AI training is very different from piracy. I’ve never downloaded a mega pack of songs and said to my friends “Listen to what I made!” I think anyone who compares OpenAI to pirates (favorably) is unwittingly helping the next set of feudal tech lords build a wall around the entirety of human creativity, and they won’t realize their mistake until the real toll booths open up.
I think AI training is very different from piracy. I’ve never downloaded a mega pack of songs and said to my friends “Listen to what I made!”
I’ve never done this. But I have taken lessons from people for instruments, listened to bands I like, and then created and played songs that certainly are influences by all of that. I’ve also taken a lot of art classes, and studied other people’s painting styles and then created things from what I’ve learned, and said “look at what I made!” Which is far more akin to what AI is doing that what you are implying here.
The whole point of copyright in the first place, is to encourage creative expression, so we can have human culture and shit.
I feel like that purpose has already been undermined by various changes to copyright law since its inception, such as DMCA and lengthening copyright term from 14 years to 95. Freedom to remix existing works is an important part of creative expression which current law stifles for any original work that releases in one person’s lifespan. (Even Disney knew this: the animated Pinocchio movie wouldn’t exist if copyright could last more than 56 years then)
Either way, giving bots the ‘right’ to remix things that were just made less than a year ago while depriving humans the right to release anything too similar to a 94 year old work seems ridiculous on both ends.
I’ll train my AI on just the bee movie. Then I’m going to ask it “can you make me a movie about bees”? When it spits the whole movie, I can just watch it or sell it or whatever, it was a creation of my AI, which learned just like any human would! Of course I didn’t even pay for the original copy to train my AI, it’s for learning purposes, and learning should be a basic human right!
That would be like you writing out the bee movie yourself after memorizing the whole movie and claiming it is your own idea or using it as proof that humans memorizing a movie is violating copyright. Just because an AI is violating copyright by outputting the whole bee movie, it doesn’t mean training the AI on copyright stuff is violating copyright.
Let’s just punish the AI companies for outputting copyright stuff instead of for training with them. Maybe that way they would actually go out of their way to make their LLM intelligent enough to not spit out copyrighted content.
Or, we can just make it so that any output made by an AI that is trained on copyrighted stuff cannot be copyrighted.
There is actually already a website where people just recreated the bee movie by hand so idk it might actually work as a legal argument.
If the solution is making the output non-copyrighted it fixes nothing. You can sell the pirating machine on a subscription. And it’s not like Netflix where the content ends when the subscription ends, you have already downloaded all the not-copyrighted content you wanted, and the internet would be full of non-copyrighted AI output.
Instead of selling the bee movie, you sell a bee movie maker, and a spiderman maker, and a titanic maker.
Sure, file a copyright infringement each time you manage to make an AI output copyrighted content. Just run it on a loop and it’s a money making machine. That’s fine by me.
Yeah, because running the AI also have some cost, so you are selling the subscription to run the AI on their server, not it’s output.
I’m not sure what is the legality of selling a bee movie maker, so you’d have to research that one yourself.
It’s not really a money making machine if you lose more money running the AI on your server farm, but whatever floats your boat. Also, there are already lawsuits based on outputs created from chatgpt, so it is exactly what is already happening.
learning should be a basic human right!
Education is a basic human right (except maybe in Usa, then it should be one there)






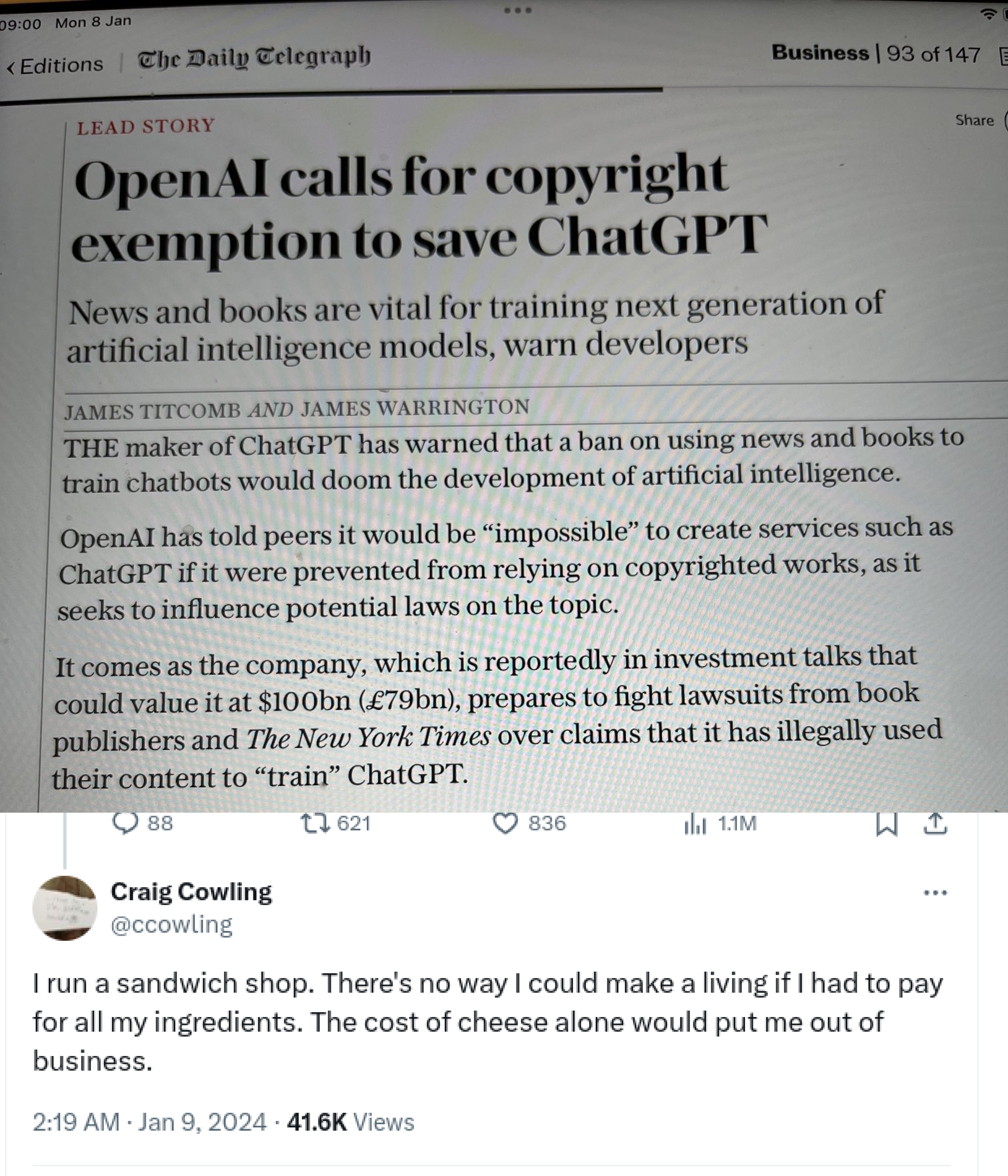{kind=link}
{kind=link}
{kind=link}