


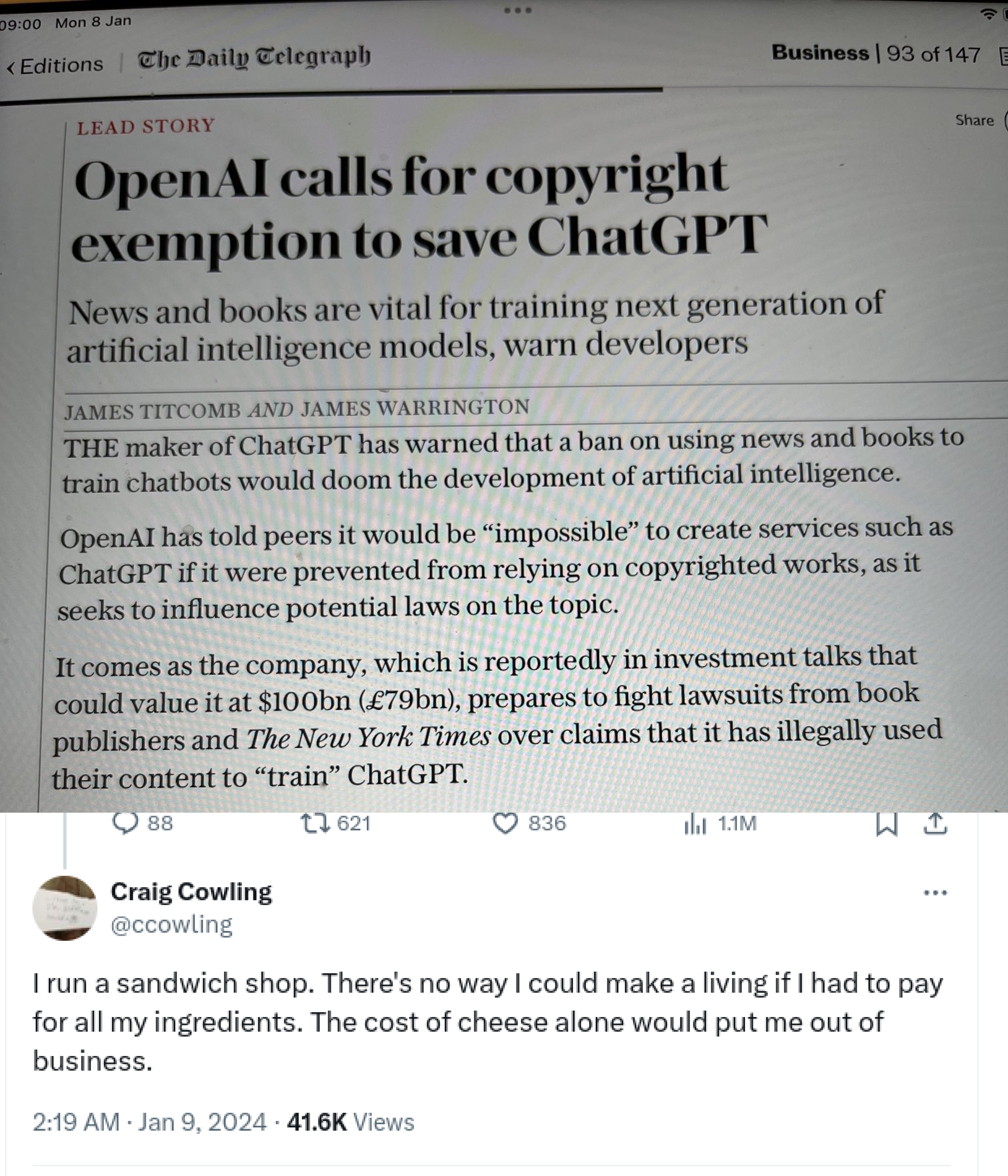
Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
Are the models that OpenAI creates open source? I don’t know enough about LLMs but if ChatGPT wants exemptions from the law, it result in a public good (emphasis on public).

The STT (speech to text) model that they created is open source (Whisper) as well as a few others:
Those aren’t open source, neither by the OSI’s Open Source Definition nor by the OSI’s Open Source AI Definition.
The important part for the latter being a published listing of all the training data. (Trainers don’t have to provide the data, but they must provide at least a way to recreate the model given the same inputs).
Data information: Sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data. Data information shall be made available with licenses that comply with the Open Source Definition.
They are model-available if anything.
I did a quick check on the license for Whisper:
Whisper’s code and model weights are released under the MIT License. See LICENSE for further details.
So that definitely meets the Open Source Definition on your first link.
And it looks like it also meets the definition of open source as per your second link.
Additional WER/CER metrics corresponding to the other models and datasets can be found in Appendix D.1, D.2, and D.4 of the paper, as well as the BLEU (Bilingual Evaluation Understudy) scores for translation in Appendix D.3.
Nothing about OpenAI is open-source. The name is a misdirection.
If you use my IP without my permission and profit it from it, then that is IP theft, whether or not you republish a plagiarized version.
So I guess every reaction and review on the internet that is ad supported or behind a payroll is theft too?
No, we have rules on fair use and derivative works. Sometimes they fall on one side, sometimes another.
If they can base their business on stealing, then we can steal their AI services, right?

Pirating isn’t stealing but yes the collective works of humanity should belong to humanity, not some slimy cabal of venture capitalists.

ingredients to a recipe may well be subject to copyright, which is why food writers make sure their recipes are “unique” in some small way. Enough to make them different enough to avoid accusations of direct plagiarism.
E: removed unnecessary snark
Yes, that’s exactly the point. It should belong to humanity, which means that anyone can use it to improve themselves. Or to create something nice for themselves or others. That’s exactly what AI companies are doing. And because it is not stealing, it is all still there for anyone else. Unless, of course, the copyrightists get there way.
Unlike regular piracy, accessing “their” product hosted on their servers using their power and compute is pretty clearly theft. Morally correct theft that I wholeheartedly support, but theft nonetheless.
Is that how this technology works? I’m not the most knowledgeable about tech stuff honestly (at least by Lemmy standards).
How do you feel about Meta and Microsoft who do the same thing but publish their models open source for anyone to use?
Well how long to you think that’s going to last? They are for-profit companies after all.
Those aren’t open source, neither by the OSI’s Open Source Definition nor by the OSI’s Open Source AI Definition.
The important part for the latter being a published listing of all the training data. (Trainers don’t have to provide the data, but they must provide at least a way to recreate the model given the same inputs).
Data information: Sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data. Data information shall be made available with licenses that comply with the Open Source Definition.
They are model-available if anything.
For the purposes of this conversation. That’s pretty much just a pedantic difference. They are paying to train those models and then providing them to the public to use completely freely in any way they want.
It would be like developing open source software and then not calling it open source because you didn’t publish the market research that guided your UX decisions.
“but how are we supposed to keep making billions of dollars without unscrupulous intellectual property theft?! line must keep going up!!”

You drank the kool-aid.

So, is the Internet caring about copyright now? Decades of Napster, Limewire, BitTorrent, Piratebay, bootleg ebooks, movies, music, etc, but we care now because it’s a big corporation doing it?
Just trying to get it straight.
You tell me, was it people suing companies or companies suing people?
Is a company claiming it should be able to have free access to content or a person?

Just a point of clarification: Copyright is about the right of distribution. So yes, a company can just “download the Internet”, store it, and do whatever TF they want with it as long as they don’t distribute it.
That the key: Distribution. That’s why no one gets sued for downloading. They only ever get sued for uploading. Furthermore, the damages (if found guilty) are based on the number of copies that get distributed. It’s because copyright law hasn’t been updated in decades and 99% of it predates computers (especially all the important case law).
What these lawsuits against OpenAI are claiming is that OpenAI is making a derivative work of the authors/owners works. Which is kinda what’s going on but also not really. Let’s say that someone asks ChatGPT to write a few paragraphs of something in the style of Stephen King… His “style” isn’t even cooyrightable so as long as it didn’t copy his works word-for-word is it even a derivative? No one knows. It’s never been litigated before.
My guess: No. It’s not going to count as a derivative work. Because it’s no different than a human reading all his books and performing the same, perfectly legal function.
It’s more about copying, really.
That’s why no one gets sued for downloading.
People do get sued in some countries. EG Germany. I think they stopped in the US because of the bad publicity.
What these lawsuits against OpenAI are claiming is that OpenAI is making a derivative work of the authors/owners works.
That theory is just crazy. I think it’s already been thrown out of all these suits.
People on Lemmy. I personally didn’t realize everyone here was such big fans of copyright and artificial scarcity.
The reality is that people hate tech bros (deservedly) and then blindly hate on everything they like by association, which sometimes results in dumbassery like everyone now dick-riding the copyright system.
The reality is that people hate the corporations using creative peoples works to try and make their jobs basically obsolete and they grab onto anything to fight against it, even if it’s a bit of a stretch.
I’d hate a world lacking real human creativity.

Personally for me its about the double standard. When we perform small scale “theft” to experience things we’d be willing to pay for if we could afford it and the money funded the artists, they throw the book at us. When they build a giant machine that takes all of our work and turns it into an automated record scratcher that they will profit off of and replace our creative jobs with, that’s just good business. I don’t think it’s okay that they get to do things like implement DRM because IP theft is so terrible, but then when they do it systemically and against the specific licensing of the content that has been posted to the internet, that’s protected in the eyes of the law
What about companies who scrape public sites for training data but then publish their trained models open source for anyone to use?
That feels a lot more reasonable and fair to me personally.
If they still profit from it, no.
Open models made by nonprofit organisations, listing their sources, not including anything from anyone who requests it not to be included (with robots.txt, for instance), and burdened with a GPL-like viral license that prevents the models and their results from being used for profit… that’d probably be fine.
I mean openais not getting off Scott free, they’ve been getting sued a lot recently for this exact copy right argument. New York times is suing them for potential billions.
They throw the book at us
Do they though, since the Metallica lawsuits in the aughts there hasnt been much prosecution at the consumer level for piracy, and what little there is is mostly cease and desists.
Kill a person, that’s a tragedy. Kill a hundred thousand people, they make you king.
Steal $10, you go to jail. Steal $10 billion, they make you Senator.
If you do crime big enough, it becomes good.
If you do crime big enough, it becomes good.
No, no it doesn’t.
It might become legal, or tolerated, or the laws might become unenforceable.
But that doesn’t make it good, on the contrary, it makes it even worse.

People don’t like when you punch down. When a 13 year old illegally downloaded a Limp Bizkit album no one cared. When corporations worth billions funded by venture capital systematically harvest the work of small creators (often with appropriate license) to sell a product people tend to care.






{kind=link}
{kind=link}
{kind=link}