


Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
Bullshit. AI are not human. We shouldn’t treat them as such. AI are not creative. They just regurgitate what they are trained on. We call what it does “learning”, but that doesn’t mean we should elevate what they do to be legally equal to human learning.
It’s this same kind of twisted logic that makes people think Corporations are People.
Ok, ignore this specific company and technology.
In the abstract, if you wanted to make artificial intelligence, how would you do it without using the training data that we humans use to train our own intelligence?
We learn by reading copyrighted material. Do we pay for it? Sometimes. Sometimes a teacher read it a while ago and then just regurgitated basically the same copyrighted information back to us in a slightly changed form.
We learn by reading copyrighted material.
We are human beings. The comparison is false on it’s face because what you all are calling AI isn’t in any conceivable way comparable to the complexity and versatility of a human mind, yet you continue to spit this lie out, over and over again, trying to play it up like it’s Data from Star Trek.
This model isn’t “learning” anything in any way that is even remotely like how humans learn. You are deliberately simplifying the complexity of the human brain to make that comparison.
Moreover, human beings make their own choices, they aren’t actual tools.
They pointed a tool at copyrighted works and told it to copy, do some math, and regurgitate it. What the AI “does” is not relevant, what the people that programmed it told it to do with that copyrighted information is what matters.
There is no intelligence here except theirs. There is no intent here except theirs.
We are human beings. The comparison is false on it’s face because what you all are calling AI isn’t in any conceivable way comparable to the complexity and versatility of a human mind, yet you continue to spit this lie out, over and over again, trying to play it up like it’s Data from Star Trek.
If you fundamentally do not think that artificial intelligences can be created, the onus is on yo uto explain why it’s impossible to replicate the circuitry of our brains. Everything in science we’ve seen this far has shown that we are merely physical beings that can be recreated physically.
Otherwise, I asked you to examine a thought experiment where you are trying to build an artificial intelligence, not necessarily an LLM.
This model isn’t “learning” anything in any way that is even remotely like how humans learn. You are deliberately simplifying the complexity of the human brain to make that comparison.
Or you are over complicating yourself to seem more important and special. Definitely no way that most people would be biased towards that, is there?
Moreover, human beings make their own choices, they aren’t actual tools.
Oh please do go ahead and show us your proof that free will exists! Thank god you finally solved that one! I heard people were really stressing about it for a while!
They pointed a tool at copyrighted works and told it to copy, do some math, and regurgitate it. What the AI “does” is not relevant, what the people that programmed it told it to do with that copyrighted information is what matters.
“I don’t know how this works but it’s math and that scares me so I’ll minimize it!”
This model isn’t “learning” anything in any way that is even remotely like how humans learn. You are deliberately simplifying the complexity of the human brain to make that comparison.
I do think the complexity of artificial neural networks is overstated. A real neuron is a lot more complex than an artificial one, and real neurons are not simply feed forward like ANNs (which have to be because they are trained using back-propagation), but instead have their own spontaneous activity (which kinda implies that real neural networks don’t learn using stochastic gradient descent with back-propagation). But to say that there’s nothing at all comparable between the way humans learn and the way ANNs learn is wrong IMO.
If you read books such as V.S. Ramachandran and Sandra Blakeslee’s Phantoms in the Brain or Oliver Sacks’ The Man Who Mistook His Wife For a Hat you will see lots of descriptions of patients with anosognosia brought on by brain injury. These are people who, for example, are unable to see but also incapable of recognizing this inability. If you ask them to describe what they see in front of them they will make something up on the spot (in a process called confabulation) and not realize they’ve done it. They’ll tell you what they’ve made up while believing that they’re telling the truth. (Vision is just one example, anosognosia can manifest in many different cognitive domains).
It is V.S Ramachandran’s belief that there are two processes that occur in the Brain, a confabulator (or “yes man” so to speak) and an anomaly detector (or “critic”). The yes-man’s job is to offer up explanations for sensory input that fit within the existing mental model of the world, whereas the critic’s job is to advocate for changing the world-model to fit the sensory input. In patients with anosognosia something has gone wrong in the connection between the critic and the yes man in a particular cognitive domain, and as a result the yes-man is the only one doing any work. Even in a healthy brain you can see the effects of the interplay between these two processes, such as with the placebo effect and in hallucinations brought on by sensory deprivation.
I think ANNs in general and LLMs in particular are similar to the yes-man process, but lack a critic to go along with it.
What implications does that have on copyright law? I don’t know. Real neurons in a petri dish have already been trained to play games like DOOM and control the yoke of a simulated airplane. If they were trained instead to somehow draw pictures what would the legal implications of that be?
There’s a belief that laws and political systems are derived from some sort of deep philosophical insight, but I think most of the time they’re really just whatever works in practice. So, what I’m trying to say is that we can just agree that what OpenAI does is bad and should be illegal without having to come up with a moral imperative that forces us to ban it.
And that’s all paid for. Think how much just the average high school graduate has has invested in them, ai companies want all that, but for free
It’s not though.
A huge amount of what you learn, someone else paid for, then they taught that knowledge to the next person, and so on. By the time you learned it, it had effectively been pirated and copied by human brains several times before it got to you.
Literally anything you learned from a Reddit comment or a Stack Overflow post for instance.
The things is, they can have scads of free stuff that is not copyrighted. But they are greedy and want copyrighted stuff, too
We all should. Copyright is fucking horseshit.
It costs literally nothing to make a digital copy of something. There is ZERO reason to restrict access to things.
The argument that these models learn in a way that’s similar to how humans do is absolutely false, and the idea that they discard their training data and produce new content is demonstrably incorrect. These models can and do regurgitate their training data, including copyrighted characters.
And these things don’t learn styles, techniques, or concepts. They effectively learn statistical averages and patterns and collage them together. I’ve gotten to the point where I can guess what model of image generator was used based on the same repeated mistakes that they make every time. Take a look at any generated image, and you won’t be able to identify where a light source is because the shadows come from all different directions. These things don’t understand the concept of a shadow or lighting, they just know that statistically lighter pixels are followed by darker pixels of the same hue and that some places have collections of lighter pixels. I recently heard about an ai that scientists had trained to identify pictures of wolves that was working with incredible accuracy. When they went in to figure out how it was identifying wolves from dogs like huskies so well, they found that it wasn’t even looking at the wolves at all. 100% of the images of wolves in its training data had snowy backgrounds, so it was simply searching for concentrations of white pixels (and therefore snow) in the image to determine whether or not a picture was of wolves or not.

Even if they learned exactly like humans do, like so fucking what, right!? Humans have to pay EXORBITANT fees for higher education in this country. Arguing that your bot gets socialized education before the people do is fucking absurd.

That seems more like an argument for free higher education rather than restricting what corpuses a deep learning model can train on
Devil’s Advocate:
How do we know that our brains don’t work the same way?
Why would it matter that we learn differently than a program learns?
Suppose someone has a photographic memory, should it be illegal for them to consume copyrighted works?
Because we’re talking pattern recognition levels of learning. At best, they’re the equivalent of parrots mimicking human speech. They take inputs and output data based on the statistical averages from their training sets - collaging pieces of their training into what they think is the right answer. And I use the word think here loosely, as this is the exact same process that the Gaussian blur tool in Photoshop uses.
This matters in the context of the fact that these companies are trying to profit off of the output of these programs. If somebody with an eidetic memory is trying to sell pieces of works that they’ve consumed as their own - or even somebody copy-pasting bits from Clif Notes - then they should get in trouble; the same as these companies.
Given A and B, we can understand C. But an LLM will only be able to give you AB, A(b), and B(a). And they’ve even been just spitting out A and B wholesale, proving that they retain their training data and will regurgitate the entirety of copyrighted material.
The solution is any AI must always be released on a strong copyleft and possibly abolish copyright outright has it has only served the powerful by allowing them to enclose humanity common intellectual heritage (see Disney’s looting and enclosing if ancestral children stories). If you choose to strengthen the current regime, don’t expect things to improve for you as an irrelevant atomised individual,
Basing your argument around how the model or training system works doesn’t seem like the best way to frame your point to me. It invites a lot of mucking about in the details of how the systems do or don’t work, how humans learn, and what “learning” and “knowledge” actually are.
I’m a human as far as I know, and it’s trivial for me to regurgitate my training data. I regularly say things that are either directly references to things I’ve heard, or accidentally copy them, sometimes with errors.
Would you argue that I’m just a statistical collage of the things I’ve experienced, seen or read?
My brain has as many copies of my training data in it as the AI model, namely zero, but “Captain Picard of the USS Enterprise sat down for a rousing game of chess with his friend Sherlock Holmes, and then Shakespeare came in dressed like Mickey mouse and said ‘to be or not to be, that is the question, for tis nobler in the heart’ or something”. Direct copies of someone else’s work, as well as multiple copyright infringements.
I’m also shit at drawing with perspective. It comes across like a drunk toddler trying their hand at cubism.
Arguing about how the model works or the deficiencies of it to justify treating it differently just invites fixing those issues and repeating the same conversation later. What if we make one that does work how humans do in your opinion? Or it properly actually extracts the information in a way that isn’t just statistically inferred patterns, whatever the distinction there is? Does that suddenly make it different?
You don’t need to get bogged down in the muck of the technical to say that even if you conceed every technical point, we can still say that a non-sentient machine learning system can be held to different standards with regards to copyright law than a sentient person. A person gets to buy a book, read it, and then carry around that information in their head and use it however they want. Not-A-Person does not get to read a book and hold that information without consent of the author.
Arguing why it’s bad for society for machines to mechanise the production of works inspired by others is more to the point.
Computers think the same way boats swim. Arguing about the difference between hands and propellers misses the point that you don’t want a shrimp boat in your swimming pool. I don’t care why they’re different, or that it technically did or didn’t violate the “free swim” policy, I care that it ruins the whole thing for the people it exists for in the first place.
I think all the AI stuff is cool, fun and interesting. I also think that letting it train on everything regardless of the creators wishes has too much opportunity to make everything garbage. Same for letting it produce content that isn’t labeled or cited.
If they can find a way to do and use the cool stuff without making things worse, they should focus on that.
I’m not the above poster, but I really appreciate your argument. I think many people overcorrect in their minds about whether or not these models learn the way we do, and they miss the fact that they do behave very similarly to parts of our own systems. I’ve generally found that that overcorrection leads to bad arguments about copyright violation and ethical concerns.
However, your point is very interesting (and it is thankfully independent of that overcorrection). We’ve never had to worry about nonhuman personhood in any amount of seriousness in the past, so it’s strangely not obvious despite how obvious it should be: it’s okay to treat real people as special, even in the face of the arguable personhood of a sufficiently advanced machine. One good reason the machine can be treated differently is because we made it for us, like everything else we make.
I think there still is one related but dangling ethical question. What about machines that are made for us but we decide for whatever reason that they are equivalent in sentience and consciousness to humans?
A human has rights and can take what they’ve learned and make works inspired by it for money, or for someone else to make money through them. They are well within their rights to do so. A machine that we’ve decided is equivalent in sentience to a human, though… can that nonhuman person go take what it’s learned and make works inspired by it so that another person can make money through them?
If they SHOULDN’T be allowed to do that, then it’s notable that this scenario is only separated from what we have now by a gap in technology.
If they SHOULD be allowed to do that (which we could make a good argument for, since we’ve agreed that it is a sentient being) then the technology gap is again notable.
I don’t think the size of the technology gap actually matters here, logically; I think you can hand-wave it away pretty easily and apply it to our current situation rather than a future one. My guess, though, is that the size of the gap is of intuitive importance to anyone thinking about it (I’m no different) and most people would answer one way or the other depending on how big they perceive the technology gap to be.
Another good question is why AIs do not mindlessly regurgitate source material. The reason is that they have access to so much copyrighted material. If they were trained on only one book, they would constantly regurgitate material from that one book. Because it’s trained on many (millions) books, it’s able to get creative. So the argument of OpenAI really boils down to: “we are not breaking copyright law, because we have used sufficient copyrighted material to avoid directly infringing on copyright”.
Eeeh, I still think diving into the weeds of the technical is the wrong way to approach it. Their argument is that training isn’t copyright violation, not that sufficient training dilutes the violation.
Even if trained only on one source, it’s quite unlikely that it would generate copyright infringing output. It would be vastly less intelligible, likely to the point of overtly garbled words and sentences lacking much in the way of grammar.
If what they’re doing is technically an infringement or how it works is entirely aside from a discussion on if it should be infringement or permitted.
Arguing why it’s bad for society for machines to mechanise the production of works inspired by others is more to the point.
I agree, but the fact that shills for this technology are also wrong about it is at least interesting.
Rhetorically speaking, I don’t know if that’s useless.
I don’t care why they’re different, or that it technically did or didn’t violate the “free swim” policy,
I do like this point a lot.
If they can find a way to do and use the cool stuff without making things worse, they should focus on that.
I do miss when the likes of cleverbot was just a fun novelty on the Internet.
I am also not really getting the argument. If I as a human want to learn a subject from a book I buy it ( or I go to a library who paid for it). If it’s similar to how humans learn, it should cost equally much.
The issue is of course that it’s not at all similar to how humans learn. It needs VASTLY more data to produce something even remotely sensible. Develop AI that’s truly transformative, by making it as efficient as humans are in learning, and the cost of paying for copyright will be negligible.
If I as a human want to learn a subject from a book, I buy it
xD
That’s good.
Dude never heard of a library. I only bought a handful of books during my degree, I would’ve been homeless if I had to buy a copy of every learning source
If I as a human want to learn a subject from a book I buy it ( or I go to a library who paid for it). If it’s similar to how humans learn, it should cost equally much.
You’re on Lemmy where people casually says “piracy is morally the right thing to do”, so I’m not sure this argument works on this platform.
I know my way around the Jolly Roger myself. At the same time using copyrighted materials in a commercial setting (as OpenAI does) shouldn’t be free.

You drank the kool-aid.
Here’s an experiment for you to try at home. Ask an AI model a question, copy a sentence or two of what they give back, and paste it into a search engine. The results may surprise you.
And stop comparing AI to humans but then giving AI models more freedom. If I wrote a paper I’d need to cite my sources. Where the fuck are your sources ChatGPT? Oh right, we’re not allowed to see that but you can take whatever you want from us. Sounds fair.
It’s not a breach of copyright or other IP law not to cite sources on your paper.
Getting your paper rejected for lacking sources is also not infringing in your freedom. Being forced to pay damages and delete your paper from any public space would be infringement of your freedom.
I mean, you’re not necessarily wrong. But that doesn’t change the fact that it’s still stealing, which was my point. Just because laws haven’t caught up to it yet doesn’t make it any less of a shitty thing to do.

When I analyze a melody I play on a piano, I see that it reflects the music I heard that day or sometimes, even music I heard and liked years ago.
Having parts similar or a part that is (coincidentally) identical to a part from another song is not stealing and does not infringe upon any law.
The original source material is still there. They just made a copy of it. If you think that’s stealing then online piracy is stealing as well.
I’m pretty sure that it’s true that citing sources isn’t really relevant to copyright violation, either you are violating or not. Saying where you copied from doesn’t change anything, but if you are using some ideas with your own analysis and words it isn’t a violation either way.
Not to fully argue against your point, but I do want to push back on the citations bit. Given the way an LLM is trained, it’s not really close to equivalent to me citing papers researched for a paper. That would be more akin to asking me to cite every piece of written or verbal media I’ve ever encountered as they all contributed in some small way to way that the words were formulated here.
Now, if specific data were injected into the prompt, or maybe if it was fine-tuned on a small subset of highly specific data, I would agree those should be cited as they are being accessed more verbatim. The whole “magic” of LLMs was that it needed to cross a threshold of data, combined with the attentional mechanism, and then the network was pretty suddenly able to maintain coherent sentences structure. It was only with loads of varied data from many different sources that this really emerged.
This is the catch with OPs entire statement about transformation. Their premise is flawed, because the next most likely token is usually the same word the author of a work chose.
And that’s kinda my point. I understand that transformation is totally fine but these LLM literally copy and paste shit. And that’s still if you are comparing AI to people which I think is completely ridiculous. If anything these things are just more complicated search engines with half the usefulness. If I search online about how to change a tire I can find some reliable sources to do so. If I ask AI how to change a tire it would just spit something out that might not even be accurate and I’d have to search again afterwards just to make sure what it told me was even accurate.
It’s just a word calculator based on information stolen from people without their consent. It has no original thought process so it has no way to transform anything. All it can do is copy and paste in different combinations.

So, is the Internet caring about copyright now? Decades of Napster, Limewire, BitTorrent, Piratebay, bootleg ebooks, movies, music, etc, but we care now because it’s a big corporation doing it?
Just trying to get it straight.

Personally for me its about the double standard. When we perform small scale “theft” to experience things we’d be willing to pay for if we could afford it and the money funded the artists, they throw the book at us. When they build a giant machine that takes all of our work and turns it into an automated record scratcher that they will profit off of and replace our creative jobs with, that’s just good business. I don’t think it’s okay that they get to do things like implement DRM because IP theft is so terrible, but then when they do it systemically and against the specific licensing of the content that has been posted to the internet, that’s protected in the eyes of the law
I mean openais not getting off Scott free, they’ve been getting sued a lot recently for this exact copy right argument. New York times is suing them for potential billions.
They throw the book at us
Do they though, since the Metallica lawsuits in the aughts there hasnt been much prosecution at the consumer level for piracy, and what little there is is mostly cease and desists.
Kill a person, that’s a tragedy. Kill a hundred thousand people, they make you king.
Steal $10, you go to jail. Steal $10 billion, they make you Senator.
If you do crime big enough, it becomes good.
If you do crime big enough, it becomes good.
No, no it doesn’t.
It might become legal, or tolerated, or the laws might become unenforceable.
But that doesn’t make it good, on the contrary, it makes it even worse.
What about companies who scrape public sites for training data but then publish their trained models open source for anyone to use?
That feels a lot more reasonable and fair to me personally.
If they still profit from it, no.
Open models made by nonprofit organisations, listing their sources, not including anything from anyone who requests it not to be included (with robots.txt, for instance), and burdened with a GPL-like viral license that prevents the models and their results from being used for profit… that’d probably be fine.
People on Lemmy. I personally didn’t realize everyone here was such big fans of copyright and artificial scarcity.
The reality is that people hate tech bros (deservedly) and then blindly hate on everything they like by association, which sometimes results in dumbassery like everyone now dick-riding the copyright system.
The reality is that people hate the corporations using creative peoples works to try and make their jobs basically obsolete and they grab onto anything to fight against it, even if it’s a bit of a stretch.
I’d hate a world lacking real human creativity.

People don’t like when you punch down. When a 13 year old illegally downloaded a Limp Bizkit album no one cared. When corporations worth billions funded by venture capital systematically harvest the work of small creators (often with appropriate license) to sell a product people tend to care.
You tell me, was it people suing companies or companies suing people?
Is a company claiming it should be able to have free access to content or a person?

Just a point of clarification: Copyright is about the right of distribution. So yes, a company can just “download the Internet”, store it, and do whatever TF they want with it as long as they don’t distribute it.
That the key: Distribution. That’s why no one gets sued for downloading. They only ever get sued for uploading. Furthermore, the damages (if found guilty) are based on the number of copies that get distributed. It’s because copyright law hasn’t been updated in decades and 99% of it predates computers (especially all the important case law).
What these lawsuits against OpenAI are claiming is that OpenAI is making a derivative work of the authors/owners works. Which is kinda what’s going on but also not really. Let’s say that someone asks ChatGPT to write a few paragraphs of something in the style of Stephen King… His “style” isn’t even cooyrightable so as long as it didn’t copy his works word-for-word is it even a derivative? No one knows. It’s never been litigated before.
My guess: No. It’s not going to count as a derivative work. Because it’s no different than a human reading all his books and performing the same, perfectly legal function.
It’s more about copying, really.
That’s why no one gets sued for downloading.
People do get sued in some countries. EG Germany. I think they stopped in the US because of the bad publicity.
What these lawsuits against OpenAI are claiming is that OpenAI is making a derivative work of the authors/owners works.
That theory is just crazy. I think it’s already been thrown out of all these suits.




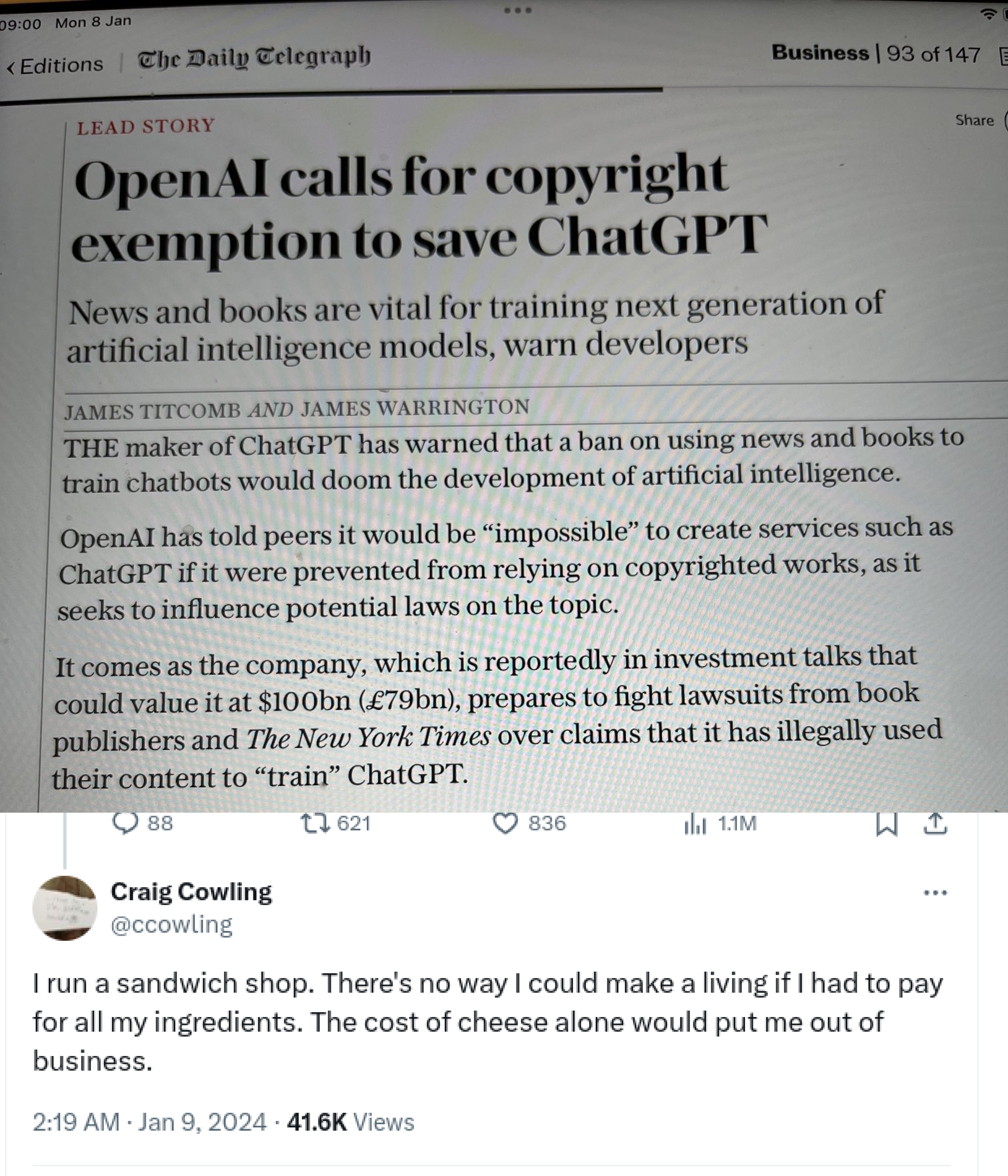{kind=link}
{kind=link}
{kind=link}