


Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
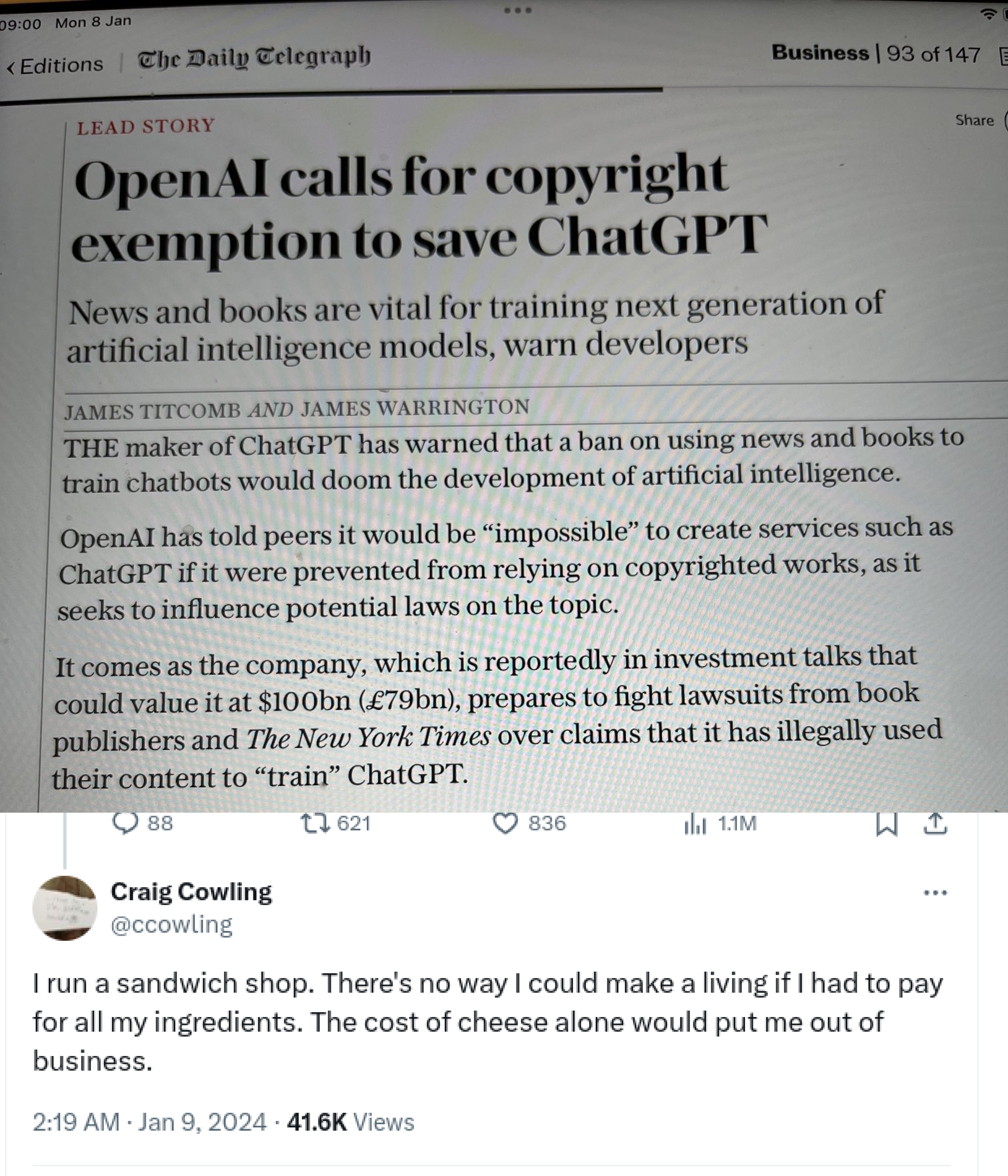
You sound like someone who has not tried to make an artistic creation for profit.
Better system for WHOM? Tech-bros that want to steal my content as their own?
I’m a writer, performing artist, designer, and illustrator. I have thought about copyright quite a bit. I have released some of my stuff into the public domain, as well as the Creative Commons. If you want to use my work, you may - according to the licenses that I provide.
I also think copyright law is way out of whack. It should go back to - at most - life of author. This “life of author plus 95 years” is ridiculous. I lament that so much great work is being lost or forgotten because of the oppressive copyright laws - especially in the area of computer software.
But tech-bros that want my work to train their LLMs - they can fuck right off. There are legal thresholds that constitute “fair use” - Is it used for an academic purpose? Is it used for a non-profit use? Is the portion that is being used a small part or the whole thing? LLM software fail all of these tests.
They can slurp up the entirety of Wikipedia, and they do. But they are not satisfied with the free stuff. But they want my artistic creations, too, without asking. And they want to sell something based on my work, making money off of my work, without asking.
Better system for WHOM? Tech-bros that want to steal my content as their own?
A better system for EVERYONE. One where we all have access to all creative works, rather than spending billions on engineers nad lawyers to create walled gardens and DRM and artificial scarcity. What if literally all the money we spent on all of that instead went to artist royalties?
But tech-bros that want my work to train their LLMs - they can fuck right off. There are legal thresholds that constitute “fair use” - Is it used for an academic purpose? Is it used for a non-profit use? Is the portion that is being used a small part or the whole thing? LLM software fail all of these tests.
No. It doesn’t.
They can literally pass all of those tests.
You are confusing OpenAI keeping their LLM closed source and charging access to it, with LLMs in general. The open source models that Microsoft and Meta publish for instance, pass literally all of the criteria you just stated.





{kind=link}
{kind=link}
{kind=link}