


Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
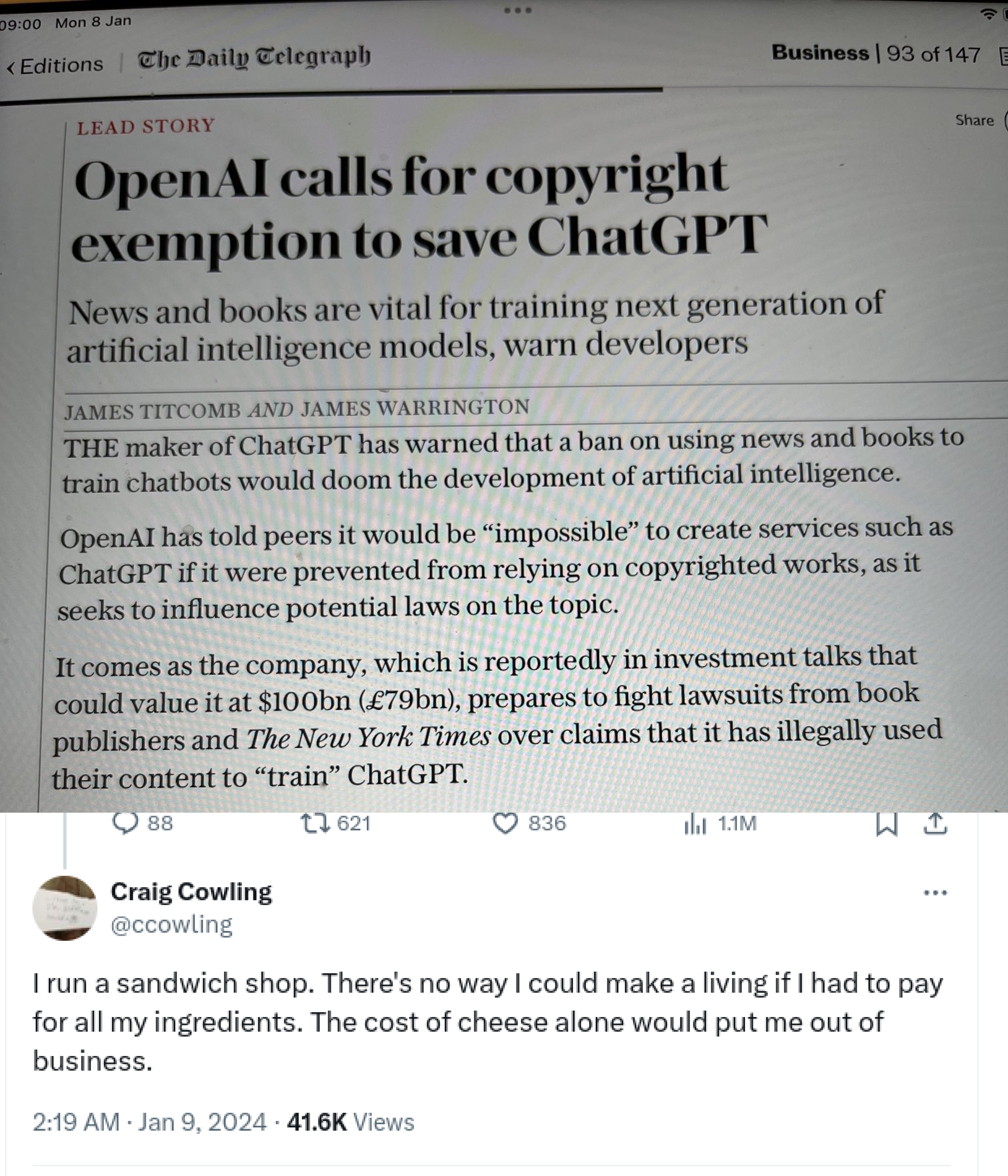
Yeah, making sandwiches also costs money! I have to pay my sandwich making employees to keep the business profitable! How do they expect me to pay for the cheese?
EDIT: also, you completely missed my point. The money making machine is the AI because the copyright owners could just use them every time it produces copyright-protected material if we decided to take that route, which is what the parent comment suggested.
They should pay for the cheese, I’m not arguing against that, but they should be paying it the same amount as a normal human would if they want access to that cheese. No extra fees for access to copyrighted material if you want to use it to train AI vs wanting to consume it yourself.
And I didn’t miss your point. My point was that the reality is already occurring since people are already suing OpenAI for ChatGPT outputs that the people suing are generating themselves, so it’s no longer just a hypothetical. We’ll see if it is a money making machine for them or will they just waste their resources from doing that.
Media is not exactly like cheese though. With cheese, you buy it and it’s yours. Media, however, is protected by copyright. When you watch a movie, you are given a license to watch the movie.
When an AI watches a movie, it’s not really watching it, it’s doing a different action. If the license of the movie says “you can’t use this license to train AI, use the other (more expensive) license for such purposes”, then AIs have extra fees to access the content that humans don’t have to pay.
Both humans and AI consume the content, even if they do not do so in the exact same way. I don’t see the need to differentiate that. It’s not like we have any idea of the mechanism by which humans consume a content to make the differentiation in the first place.




{kind=link}
{kind=link}
{kind=link}