

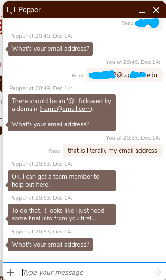
I also reached out to them on Twitter but they directed me to this form. I followed up with them on Twitter with what happened in this screenshot but they are now ignoring me.
Probably, from what I can see the address in question isn’t really that exotic. but an email regex that validates 100% correctly is near impossible. And then you still don’t know if the email address actually exists.
I’d just take the user at their word and send an email with an activation link to the address that was supplied. If the address is invalid, the mail won’t get delivered. No harm done.
Actually, one of our customers found out the hard way that there is harm in sending emails to invalid addresses. Too many kickbacks and cloud services think you’re a bot. Prevented the customer from being able to send emails for 24 hours.
This is the result of them “requiring” an email for customers but entering a fake one if they didn’t want to provide their email, and then trying to send out an email to everyone.
Our software has an option to disable that requirement but they didn’t want to use it because they wanted their staff to remember to ask for an email address. It was not a great setup but they only had themselves to blame.
My guess is that would also occur with valid but non-existing e-mail addresses no? The regex would not be a remedy there anyway.
Of course you should only use the supplied e-mail address for things like mass mailings once it has been verified (i.e. the activation link from within the mail was clicked)
That’s exactly what they did. They used something like noaddress@ourbusniess.com to get around the checks we had in place. I’ve intentionally been vague but most people will give their email address to our customers and won’t give a fake one. So under normal situations the amount of bounce backs would be minimal: fat fingering, hearing them incorrectly, or people misremembering their email. Not enough to worry about. Never thought we’d come across a customer intentionally putting in bad email addresses for documentation purposes. They could have just asked us to make the functionality they wanted.
Email standard sucks anyway. By the official standard, User@email.com and user@email.com should be treated as separate users…
Personally I don’t think that sucks or is even wrong. Case-independent text processing is more cumbersome. ‘U’ and ‘u’ are two different symbols. And you have to make such rules for every language a part of your processing logic.
If people can take case-dependence for passwords (or official letters and their school papers), then it’s also fine for email addresses.
The actual problem is cultural, coming from DOS and Windows where many things are case-independent. It’s an acquired taste.
Im with the earlier “yeah… No.”
Because
“If people can take case-dependence for passwords”
They cant now do they ? If they could passwords would be a-okay and there wouldn’t be any need for stickies on monitors, password managers, biometrics, SSO, MFA and passwordless authentication.
The dumbest idea in computing is assuming everyone is as smart as you.
They aren’t. Why isn’t *nix any bigger? Here’s your answer. People are stupid.
Why did IT only finally took off with windows 3.11? because people could understand that. Barely. Most of us where way to dumb for everything which came before.
Why does ipv6 acception takes so long? Because people are stupid and don’t get it. Nobody really gets hex. So they just stay with what they can read and more or less get. Even the hardest part of ip4, subnetting, has an easy way out: just add 255.255.255.0 in there and it works. Doesnt work? Keep replacing 255 with zeros and eventually it will. Subnetting on ipv6? No idea. Let’s just disable ipv6 on the internal lan and leave everything on ipv4. Zero migration, zero risk, zero training needed.
Why do so many companies only go half assed into cloud? Because they don’t get it.
Powershell? Only half, a third even, of the admins truly get it.
I could go on.
Succes is build on simplicity.

‘U’ and ‘u’ are two different symbols. And you have to make such rules for every language a part of your processing logic.
Unicode has standard rules for case folding, which includes the rules for all languages supported by Unicode. Case-insensitive comparisons in all good programming languages uses this data.
Note that you can’t simply convert both strings to uppercase or lowercase to compare them, as then you’ll run into the Turkish i problem: https://haacked.com/archive/2012/07/05/turkish-i-problem-and-why-you-should-care.aspx/
But then you run into the issue of incredibly trivial impersonation on any email service which doesn’t reserve all variants of registered names
I know at least one bank that has case-insensitive password in their app 🌚

The best of validation is just to confirm that the email contains a and a . and if it does send it an email with a confirmation link.
TLDs are valid in emails, as are IP V6 addresses, so checking for a . is technically not correct. For example a@b and a@[IPv6:2001:db8::1] are both valid email addresses.
I feel like using a@[IPv6:2001:db8::1] is asking for trouble everywhere online.
But its tempting to try out, not many people would expect this.


We’re gonna need a bigger regex
TLDs could theoretically have MX records too! Email addresses as specified also support IPv6 addresses! The regex would need to be .+ and at this point it’s probably easier to just send an email.
I’m with you, and I agree that is technically correct, but I believe the sheer number of people who might accidentally write “gmail” instead of “gmail.com” compared to people using an IPv6 address (seems like a spam bot) or using a TLD like “admin@com” make requiring the dot worthwhile.



{kind=link}
{kind=link}