



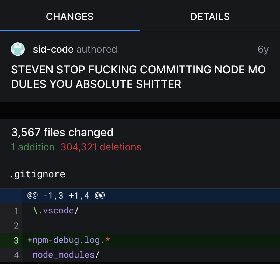
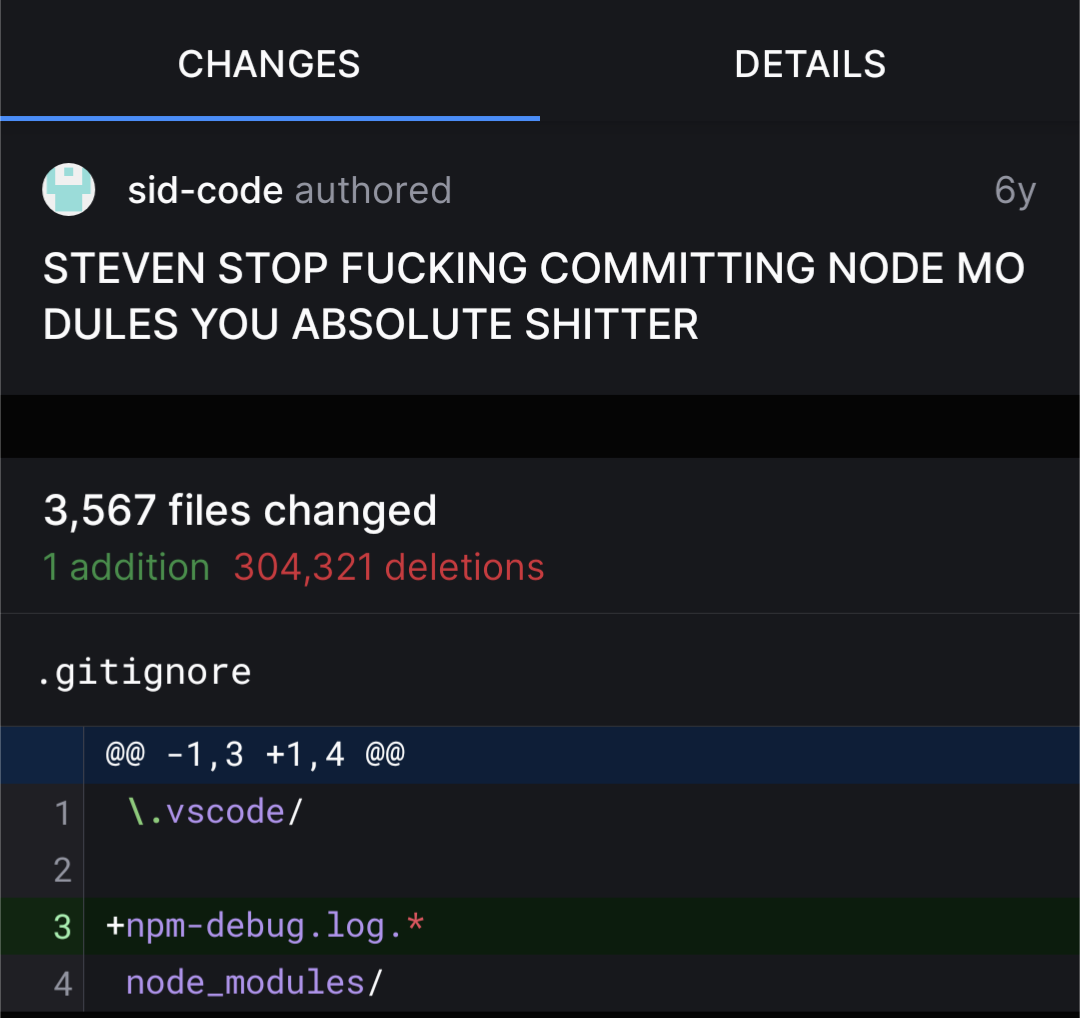
Creating a mucj larger dl. What a dick.
Wow, that’s 300k lines of text that anyone, who clones the repo, has to download.

Correct me if I’m wrong, but it’s not enough to delete the files in the commit, unless you’re ok with Git tracking the large amount of data that was previously committed. Your git clones will be long, my friend
See this is the kind of shit that bothers me with Git and we just sort of accept it, because it’s THE STANDARD. And then we crank attach these shitty LFS solutions on the side because it don’t really work.
Give me Perforce, please.
What was perforce’s solution to this? If you delete a file in a new revision, it still kept the old data around, right? Otherwise there’d be no way to rollback.
Yes but Perforce is a (broadly) centralised system, so you don’t end up with the whole history on your local computer. Yes, that then has some challenges (local branches etc, which Perforce mitigates with Streams) and local development (which is mitigated in other ways).
For how most teams work, I’d choose Perforce any day. Git is specialised towards very large, often part time, hyper-distributed development (AKA Linux development), but the reality is that most teams do work with a main branch in a central location.
You’d have to rewrite the history as to never having committed those files in the first place, yes.
And then politely ask all your coworkers to reset their working environments to the “new” head of the branch, same as the old head but not quite.
Chaos ensues. Sirens in the distance wailing.
If this was committed to a branch would doing a squash merge into another branch and then nuking the old one not do the trick?
Rewrite history? Difficult.
Start a new project and nuke the old one? Finger guns.

No, don’t do that. That modifies the commit hashes, so tags no longer work.
git clone --filter=blob:none is where it’s at.

What are you smoking? Shallow clones don’t modify commit hashes.
The only thing that you lose is history, but that usually isn’t a big deal.
--filter=blob:none probably also won’t help too much here since the problem with node_modules is more about millions of individual files rather than large files (although both can be annoying).
I don’t understand how we’re all using git and it’s not just some backend utility that we all use a sane wrapper for instead.
Everytime you want to do anything with git it’s a weird series or arcane nonsense commands and then someone cuts in saying “oh yeah but that will destroy x y and z, you have to use this other arcane nonsense command that also sounds nothing like you’re trying to do” and you sit there having no idea why either of them even kind of accomplish what you want.
I can’t see past the word wrap implementation in that UI. Mo dules indeed.

Do I really have to escape my dots in a .gitignore?

I really don’t think so. The documentation says nothing of the like.
Maybe someone thought it’s a regex pattern, where escaping dots would make sense. But yeah, it mostly works like glob patterns instead.



{kind=link}
{kind=link}